

By Jarred Walton published about 6 hours ago





The AMD RDNA 3 architecture has finally been officially unwrapped, alongside the new $999 Radeon RX 7900 XTX and $899 Radeon RX 7900 XT graphics cards. These are set to go head-to-head with the best graphics cards, and AMD seems like it might have a legitimate shot at the top of the GPU benchmarks hierarchy. Here’s what we know.
First, most of the details align with what was already expected and covered in our AMD RDNA 3 architecture and RX 7000-series GPUs. RDNA 3 will use chiplets, with a main GCD (Graphics Compute Die) and up to six MCDs (Memory Cache Dies). In addition, there are a lot of under-the-hood changes to the architecture, including more Compute Units and a lot more GPU shaders compared to the previous generation.
Fundamentally, AMD continues to focus on power and energy efficiency and has targeted a 50% improvement in performance per watt with RDNA 3 compared to RDNA 2. We know Nvidia’s RTX 4090 and Ada Lovelace pushed far up the voltage and frequency curve, and as we showed in our RTX 4090 efficiency scaling, power limiting the RTX 4090 to 70% greatly boosted Nvidia’s efficiency. However, AMD apparently feels no need to dial the power use up to 11 at default.
Let’s start with a quick overview of the core specifications, comparing AMD’s upcoming GPUs with the top previous generation RDNA 2 and Nvidia’s RTX 4090.
| Graphics Card | RX 7900 XTX | RX 7900 XT | RX 6950 XT | RTX 4090 | RTX 4080 | RTX 3090 Ti |
|---|---|---|---|---|---|---|
| Architecture | Navi 31 | Navi 31 | Navi 21 | AD102 | AD103 | GA102 |
| Process Technology | TSMC N5 + N6 | TSMC N5 + N6 | TSMC N7 | TSMC 4N | TSMC 4N | Samsung 8N |
| Transistors (Billion) | 58 | 58 – 1MCD | 26.8 | 76.3 | 45.9 | 28.3 |
| Die size (mm^2) | 300 + 222 | 300 + 185 | 519 | 608.4 | 378.6 | 628.4 |
| SMs / CUs / Xe-Cores | 96 | 84 | 80 | 128 | 76 | 84 |
| GPU Cores (Shaders) | 12288 | 10752 | 5120 | 16384 | 9728 | 10752 |
| Tensor Cores | N/A | N/A | N/A | 512 | 304 | 336 |
| Ray Tracing “Cores” | 96 | 84 | 80 | 128 | 76 | 84 |
| Boost Clock (MHz) | 2300 | 2000 | 2310 | 2520 | 2505 | 1860 |
| VRAM Speed (Gbps) | 20? | 20? | 18 | 21 | 22.4 | 21 |
| VRAM (GB) | 24 | 20 | 16 | 24 | 16 | 24 |
| VRAM Bus Width | 384 | 320 | 256 | 384 | 256 | 384 |
| L2 / Infinity Cache | 96 | 80 | 128 | 72 | 64 | 6 |
| ROPs | 192 | 192 | 128 | 176 | 112 | 112 |
| TMUs | 384 | 336 | 320 | 512 | 304 | 336 |
| TFLOPS FP32 (Boost) | 56.5 | 43.0 | 23.7 | 82.6 | 48.7 | 40.0 |
| TFLOPS FP16 (FP8) | 113 | 86 | 47.4 | 661 (1321) | 390 (780) | 160 (320) |
| Bandwidth (GBps) | 960? | 800? | 576 | 1008 | 717 | 1008 |
| TDP (watts) | 355 | 300 | 335 | 450 | 320 | 450 |
| Launch Date | Dec 2022 | Dec 2022 | May 2022 | Oct 2022 | Nov 2022 | Mar 2022 |
| Launch Price | $999 | $899 | $1,099 | $1,599 | $1,199 | $1,999 |


AMD has two variants of the Navi 31 GPU coming out. The higher spec RX 7900 XTX card uses the fully enabled GCD and six MCDs, while the RX 7900 XT has 84 of the 96 Compute Units enabled and only uses five MCDs. The sixth MCD is technically still present on the cards, but it’s either a non-functional die or potentially even a dummy die. Either way, it will be fused off, and it’s not connected to the extra 4GB of GDDR6 memory, so there won’t be a way to re-enable the extra MCD.
Compared to the competition, the RX 7900 XTX still technically comes in behind the RTX 4090 in raw compute, and Nvidia has a lot more AI processing power with its tensor cores. But we also have to remember that the RX 6950 XT managed to keep up with the RTX 3090 Ti at 1080p and 1440p and was only about 5% behind at 4K. That’s despite having theoretically 40% less raw compute. So, when the RX 7900 XTX on paper has 32% less compute than the RTX 4090, we don’t actually know what that will mean in the real world of performance benchmarks.
Also, note that AMD’s presentation says 61 teraflops while our figure is 56.5 teraflops. That’s because AMD’s RDNA 3 has a split clock domain for efficiency purposes. The front end (render outputs and texturing units, perhaps) runs at 2.5 GHz, while the shaders run at 2.3 GHz. We used the 2.3 GHz value since the teraflops come from the shaders. Of course, these are “Game Clocks,” which, at least with RDNA 2, were a conservative estimate of real-world clocks while running actual games. (That’s the same for Nvidia’s Ada Lovelace and Intel’s Arc Alchemist, which both tend to run 150–250 MHz higher than the stated boost clock values in our testing.)
AMD also has a higher boost clock relative to the Game Clock, which is where it gets the 61 teraflops figure — the boost clock on the RX 7900 XT is 2.5 GHz. But, again, we’ll need to test the hardware in a variety of games to see where the actual clocks land. With RDNA 2, we found the boost clocks were pretty consistently what we saw in games, maybe even a bit low, so consider the 56.5 teraflops figure a very conservative estimate.
Of course, the bigger deal isn’t how RX 7900 XT stacks up against the RTX 4090 but rather how it will compete with the RTX 4080. It has more memory and memory bandwidth, plus 16% more compute. So even if the performance per clock on the RDNA 3 shaders dropped a bit (more on this in a second), AMD looks like it should be very competitive with Nvidia’s penultimate RTX 40-series part, especially since it costs $200 less.
With the high-level overview out of the way, let’s dig into some architectural details. Unfortunately, AMD is keeping some things under wraps, so we’re not entirely sure about the memory clocks right now, and we’ve asked for more information on other parts of the architecture. We’ll fill in the details as we get them, but some things might remain unconfirmed until the RDNA 3 launch date on December 13.
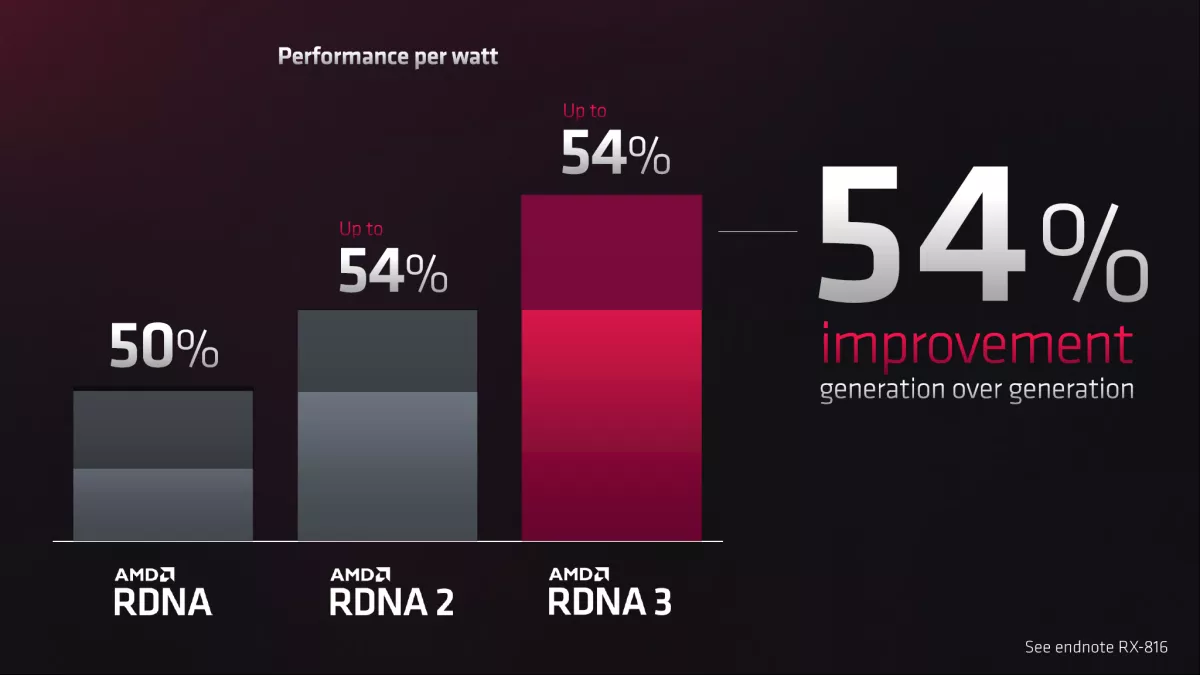
AMD has said a lot about energy efficiency with the past two generations of RDNA architectures, and RDNA 3 continues that focus. AMD claims up to a 54% performance per watt improvement compared to RDNA 2, which in turn was 54% better PPW than RDNA. In the past three generations, AMD’s efficiency has skyrocketed — and that’s not just marketing speak.
If you look at the RX 6900 XT as an example, it’s basically double the performance of the previous generation RX 5700 XT at 1440p ultra. Meanwhile, it consumes 308W in our testing compared to 214W on the 5700 XT. So that’s a 38% improvement in efficiency, just picking the two fastest RDNA 2 and RDNA offerings at the time of launch.
How does AMD continue to improve efficiency? Of course, a big part of the latest jump comes thanks to the move from TSMC N7 to N5 (7nm to 5nm), but the architectural updates also help.Image 1 of 4




The new RDNA 3 unified compute unit has 64 dual-issue stream processors (GPU shaders). That’s double the amount of RDNA 2 per compute unit, and AMD can send different workloads to each SIMD unit — or it can have both working on the same type of instruction. It’s interesting to note that the latest AMD, Intel, and Nvidia GPUs are now all using 128 shaders for each major building block — Compute Units (CUs) for AMD, Streaming Multiprocessors (SMs) for Nvidia, and Xe Vector Engines (XVEs) for Intel.
[Note: AMD has some details saying it’s still 64 Stream Processors per Compute Unit. We’re trying to get some clarification on why the number of ALUs has doubled but the SP counts remained the same. We’ll update when we get a good answer.]
Along with doubling the GPU shaders per CU, AMD has increased the total number of CUs from 80 to 96. Gen over gen, AMD’s Navi 31 has 2.4 times as many shaders as Navi 21, and the power draw only increased by 18%.
AMD also increased the performance of its AI Accelerators, which it hasn’t really talked about much. We’re not sure about the raw compute power, but we do know that the AI accelerators support both INT8 and BF16 (brain-float 16-bit) operations. So they’re probably at least partially similar to Nvidia’s tensor cores, but the total number of supported instruction sets aren’t the same. Regardless, AMD says the new AI accelerators provide up to a 2.7x improvement — double the number, more CUs, and slightly higher throughput combined would get there.
Finally, AMD says it has optimized its Ray Accelerators and that the RDNA 3 versions can handle 1.5x as many rays, with new dedicated instructions and improved BVH (ray/box) sorting and traversal. What that means in the real world still isn’t totally clear, but we definitely expect a large leap in ray tracing performance along with improved rasterization performance. Will it be enough to catch Nvidia? We’ll have to wait and see.Image 1 of 4




Besides the compute units, a lot of other areas have received significant updates with RDNA 3. One big addition is the AMD Radiance Display Engine, or basically the video output support. In addition, AMD has upgraded its RDNA 3 GPUs with support for DisplayPort 2.1 (basically a rebadging and cleanup of DisplayPort 2.0 — everything that was DP2.0 is now DP2.1).
That makes AMD the second GPU company to support DP2.x, with Intel’s Arc being the first. Except Intel only supports 10 Gbps per lane (UHBR10), or 40 Gbps total, and DisplayPort 2.1 supports up to 20 Gbps (UHBR20), or 80 Gbps total. AMD doesn’t support 20 Gbps either, apparently opting for the 13.5 Gbps (UHBR13.5) intermediate level of support. That gives AMD up to 54 Gbps total bandwidth, which is basically double what you can get from DP1.4a.
With DSC (Display Stream Compression), that means AMD has the potential to support up to 480 Hz refresh rates on a 4K monitor, or 165 Hz on an 8K display using its DisplayPort 2.1 ports. And to go along with that, the first DisplayPort 2.1 monitors and TVs should start arriving in early 2023.
AMD has also significantly overhauled the media engine with RDNA 3. This was already more or less revealed, but Navi 31 has dual media engines that are fully capable of supporting two simultaneous 8K60 streams — either encoding, decoding, or they can team up and boost the performance of encoding a single stream.
Another update on the video engine is support for AV1, which now means all three GPU vendors have full hardware encode/decode support for AV1. The uptake of AV1 has been a bit slow up until now, but hopefully, we’ll see a wide range of software solutions and streaming services that will move to support AV1 over H.264.
The video engines are clocked higher than before (we’re not sure how much higher), and AMD also notes that it has AI-enhanced video encode. We’re interested in seeing what that means in terms of quality and performance and will be looking forward to doing some video encoding tests once the hardware is available.
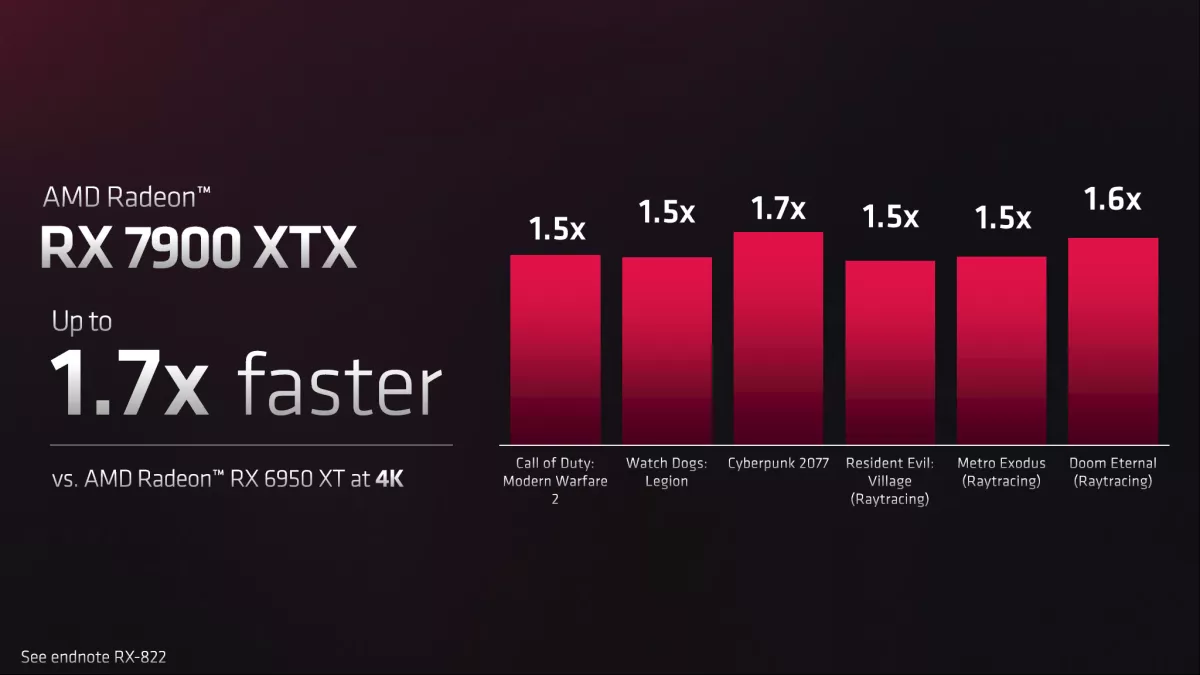
AMD shared some initial performance figures for the Radeon RX 7900 XTX. As with all manufacturer-provided benchmarks, we can’t vouch for the veracity of the above performance claims (yet), and there’s a good chance AMD has selected the above games for a reason. Still, that reason might be giving people a wider cross-sectional view of performance, showing a 50% to 70% improvement relative to the previous generation RX 6950 XT.
If we take these figures at face value, what would that mean for overall performance? At 4K ultra, our GPU benchmarks have the RTX 4090 outperforming the RX 6950 XT by 63%. That’s for traditional rasterization games. In our DXR test suite, the RTX 4090 is … okay, this is going to be painful, but at 4K in DXR, the 4090 is 204% faster. That’s without any form of upscaling. At 1440p, the gap drops a bit to 168% faster, but it’s still a gaping chasm.
50% faster, or even 60% faster, would put the RX 7900 XTX pretty close to the RTX 4090 in rasterization performance. Even with 20% more Ray Accelerators and with 50% higher performance on those Ray Accelerators, that would be, at most, around 80% higher ray tracing performance. Nvidia’s RTX 4090 would be about 70% faster at 4K, or perhaps only 50% faster at 1440p.Image 1 of 5




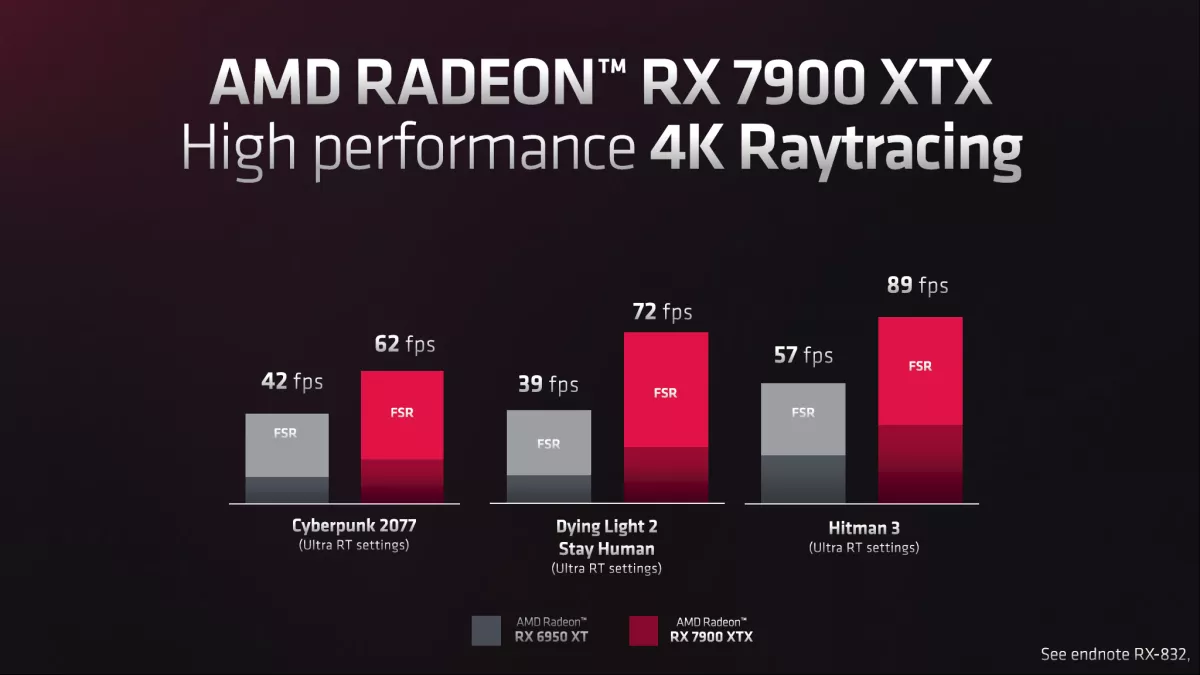
Finally, AMD talked more about its FidelityFX Super Resolution (FSR) technology. Right now, a few versions of FSR are available. The original FSR (1.x) uses spatial upscaling and can basically be integrated into drivers for things like Radeon Super Resolution (RSR). Meanwhile, the newer FSR 2.0 and 2.1 use temporal upscaling and have similar inputs to DLSS and XeSS: motion vectors, depth buffer, and current plus previous frame buffers.
AMD currently has over 216 games and applications that use FSR, but most of those are FSR 1.x implementations — again, it’s easy to integrate and open source, and it’s been available for over a year. FSR 2.0 is far newer, having first arrived in May 2022. FSR 2.1 tunes the algorithm to help eliminate ghosting and further improve image quality, and it’s only in a handful of games right now.
Looking forward, AMD’s FSR continues to gain traction. We’d love to see FSR2 use overtake FSR1 because it offers a higher-quality experience, but it’s fine for games to include both. There are use cases (like low-end graphics cards and integrated graphics) where FSR1 might still be preferable for some users. But AMD isn’t done with FSR.
FSR3 is coming sometime next year. It will look to do some form of frame generation or interpolation, somewhat similar to what Nvidia is doing with DLSS 3. AMD hasn’t revealed many details, probably partly because FSR3 isn’t even fully defined or finished yet, but in early testing, it’s seeing up to a 2x boost in performance for GPU-limited games.

There’s more to cover with RDNA 3 and the Radeon RX 7900-series cards, but we’re in meetings for the rest of the day. You can see the full slide deck below, which also gets into the AMD Advantage program coming to desktops, further performance gains for all-AMD systems and laptops, and more.
Overall, RDNA 3 and the RX 7900 XTX sound extremely promising. Even if AMD can’t quite match the raw performance of the RTX 4090, the $999 price tag absolutely deserves praise. Of course, we’ll see how the hardware stacks up in our own testing once the GPUs launch in December, but AMD looks like it will once again narrow the gap between its cards and what Nvidia has to offer.
The GPU chiplets approach clearly has some advantages as well. Nvidia currently has a 608mm^2 chip made on a custom TSMC N4 node (tuned N5), plus the 379mm^2 chip in the RTX 4080 and a 295mm^2 AD104 that will presumable go into a future RTX 4070. AMD’s Navi 31 GCD basically has the same size leading-edge process and a die size that’s similar to the AD104, but with MCDs made on a previous N6 node. It’s an obvious pricing advantage, and the RX 7900-series cards will give AMD something to chew on.
Will it be enough? That’s a bit more difficult to say. We also need to factor in Nvidia’s extras, like DLSS support. FSR and FSR2 work on “everything,” more or less, so AMD’s work benefits AMD, Intel, and Nvidia GPU owners. That’s nice, but if a game you want to play supports DLSS, it’s generally a better image quality than FSR2 (and definitely better than FSR1).
Perhaps the RTX 4080 12GB was canceled because of how badly it would have done against a similarly priced RX 7900 XT. We’ll still see that GPU, maybe in January, and hopefully at a lower price. If not, the potential to get more performance and more VRAM for the same cost will definitely favor AMD.
https://www.tomshardware.com/news/amd-rdna-3-and-radeon-rx-7900-xtx-xt-revealed

